GitHub Trending #1 的 last30days-skill:AI Agent 的近期情报层是怎么做出来的

先说结论,再展开。
mvanhorn/last30days-skill 最近拿到 GitHub Trending 当日 #1,还上了 Trendshift 榜。但真正值得看的不是 star 曲线,而是它把「近期情报」当成 Agent Skill 来做的这个思路。
我看完 v3.8.3 的源码,最大的感受是:这不是又一个搜索工具,也不是「更强的 Prompt」。它是给 Agent 加了一层专门盯着过去 30 天的情报输入——Reddit 评论、X 热帖、YouTube 转录、TikTok 互动、HN 讨论、Polymarket 赔率、GitHub 提交,一次并行拉齐,再交给 LLM 做带来源的综合判断。
一个具体场景:明天要见一个 CEO
你明天要跟某家 AI 公司创始人聊合作。传统流程是:
- Google 一下他名字。回来一堆 2023 年的 LinkedIn 简介、旧采访。
- 手工翻 X,看看最近发了什么。
- 打开 GitHub 看提交历史。
- 也许再刷一下 Reddit 有没有人聊他。
- 拼凑出一份「大概这个人在忙什么」的判断。
一个下午没了。而且到了会议现场,还是会漏一两条关键动态。
换成 last30days,一条命令:
/last30days Peter Steinberger
十分钟后你拿到的是:他这个月加入 OpenAI 的 Codex 团队,和 Anthropic 就第三方 Agent 封禁问题公开吵架,GitHub 合并了 22 个 PR、通过率 85%,正在自研跨设备 Agent 控制系统「LobsterOS」,r/ClaudeCode 上有一条 569 赞的帖子在讨论他,还引用了一句用户原话。这些证据分别来自 X、GitHub、Reddit、YouTube 转录,每一条都能点回原始出处。
这不是「更全的搜索结果」。这是把「过去 30 天真实讨论」当成一份带证据的情报稿交到你手上。
它和普通搜索的差别,用一张图说清楚
普通搜索大多回答一个问题:“有哪些网页提到了这个词?”
last30days 换了个问题:“过去 30 天,人们在哪些地方真正讨论了它?哪些讨论有互动?哪些证据可以互相印证?哪些来源太薄,需要提醒用户?”
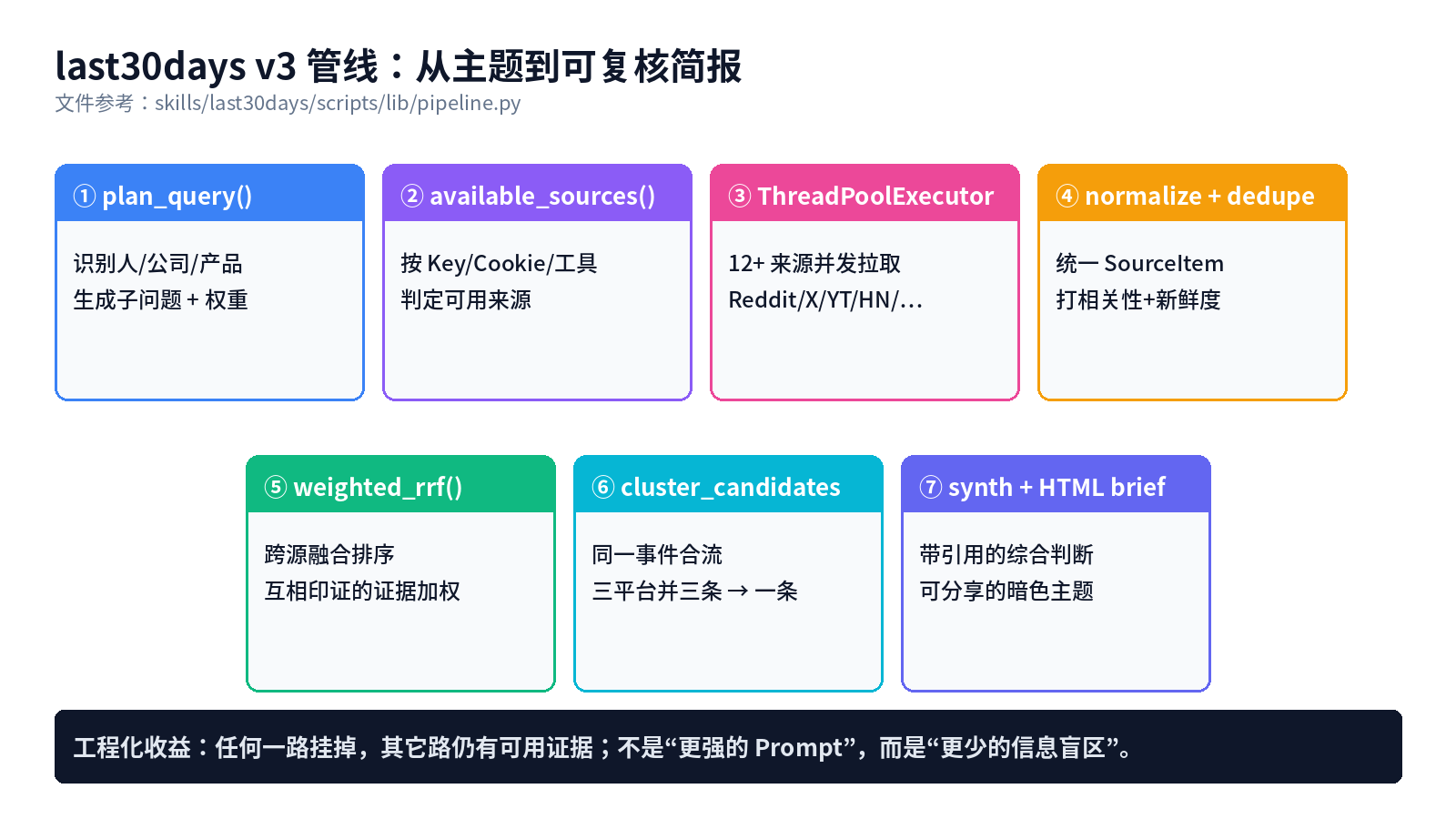
这个差别不是 Prompt 层面的差别,是管线层面的差别。v3 版本的核心流程在 skills/last30days/scripts/lib/pipeline.py,我按代码结构拆一下:
plan_query()——先识别主题,判断是人、公司、还是"X vs Y"比较,生成子问题和来源权重。这是 v3 相比 v2 最大的升级,v2 只会搜关键词,v3 会先想清楚"该搜谁"。available_sources()——按当前机器上的工具、Cookie、API Key,判定哪些来源可用。缺 Key 就跳过,不会硬碰壁。ThreadPoolExecutor——12+ 来源并发拉取。Reddit、X、YouTube、TikTok、HN、Polymarket、GitHub、Digg、Perplexity……不是串行 12 次,是一次并发。normalize()+dedupe——不同平台的字段完全不同,这一步把结果统一成SourceItem,打上本地相关性、时间新鲜度、互动强度的分数。weighted_rrf()——用带权重的 RRF 融合排序。互相印证的证据会被加权:一条新闻同时在 Reddit 和 HN 被讨论,比只在一处出现的更靠前。cluster_candidates()——同一事件的跨源合流。同一场活动,X 讨论、Reddit 讨论、YouTube 反应视频,合并成一个聚类,而不是三条独立结果。- 最后交给 LLM 做综合判断,可选输出成暗色主题的 HTML 简报(
--emit=html),能直接丢进 Slack 或 Notion。
这个管线设计比"接更多 API"重要得多。任何一路挂掉,其它路仍然有可用证据;每一条结论都能追溯到具体来源。它把研究工程化了,而不是把 Prompt 更神秘化了。
13+ 来源,按 Key 分成三档

这里最容易被忽略的点是:v3.8.3 版本把 Reddit 做到了"完全免费也能用"的状态。
以前拿 Reddit 评分需要 ScrapeCreators(付费)或者官方 API(限速严)。这版加了 arctic-shift 归档补分和 shreddit 列表页拉分,头条 + 顶评 + 分数三件套零 Key 就能跑。这个细节我在源码 lib/reddit_arctic.py 里看到实现,作者做了批量、限速、缓存和优雅降级——不是随手糊的一层。
三档配置的意思是:
- 免费即用:Reddit 含评论、Hacker News、Polymarket、GitHub、arXiv。装完就能跑。
- 浏览器 Cookie:X(从 Chrome/Firefox 读登录态)、YouTube 转录(yt-dlp)、Bluesky、TruthSocial。都是你日常就有的东西,不用再申请 API。
- API Key 加持:ScrapeCreators 一把钥匙开三扇门(TikTok、Instagram、Threads),加 Perplexity 的 Sonar/Search API/Deep Research,加 Brave 搜索,加 XAI/OpenAI 做模型判官。ScrapeCreators 前 10000 次免费。
一个非常聪明的设计:所有 Key 都是可选的,缺一个降级一层,不会因为你没有某个 Key 就整体崩掉。README 有句话我很认同:“每个平台都是它自己的花园,但你带上自己的钥匙,就能让 Agent 一次进 12 座花园。”
v3 最好玩的新功能:一条命令跑三家横评

对比类研究是 Agent 最容易失控的场景。手工做的话,你会不自觉地对某一家收集得多、另一家收集得少,结论就飘了。
v3 加了 --competitors:
/last30days OpenAI --competitors
引擎会做这几件事:
- 让宿主推理模型通过 WebSearch 找出 Top 2 竞品(Anthropic、xAI)。
- 对每一家分别跑一整条完整管线,保存
*-raw.md。 - 传入一个 per-entity
--competitors-planJSON,保证三家用同样的深度和同样的评估维度。 - 最后把三份合并成对比表 + 综合结论,同事件会跨家聚类。
也可以直接 /last30days "OpenAI vs Anthropic vs xAI",走同一条并行管线。实现在 lib/competitors.py 的 discover_competitors()。这个功能是我想抄进自己 Agent 里的头一批灵感来源。
对比不是"多写一段 Prompt",是"要保证每一家收集的证据量是公平的"。这一点 v3 做对了。
五分钟本地跑通:以 Hermes 为例
最小可用路径,我按自己在 Hermes 里跑的顺序写出来。
1. 装 Skill(Hermes 用户):
hermes skills install mvanhorn/last30days-skill --force
装到 ~/.hermes/skills/research/last30days/。其它宿主参考 npx skills add mvanhorn/last30days-skill -g,官方支持 50+ 宿主。
2. 装可选依赖:
# Python 3.12+ 是硬要求
python3 --version
# YouTube 转录靠 yt-dlp
brew install yt-dlp # macOS
# Linux: pipx install yt-dlp
# Digg 集群(可选)
npm i -g @mvanhorn/printing-press-library
# 装完确认 $HOME/.local/bin 在 PATH
3. 第一次跑:
/last30days AI Agent evaluation
第一次会走 Setup 向导:问你要不要读浏览器 Cookie(X 认证)、要不要装 yt-dlp、要不要顺手申请 ScrapeCreators Key(10000 次免费,GitHub 登录 30 秒搞定)。全部拒绝也没关系,能跑,只是来源少一点。
4. 常用运行姿势:
# 生成一份 HTML 简报,可分享
/last30days OpenClaw --emit=html
# 竞品对比
/last30days Cursor --competitors
# 招聘信号(判断某家公司战略方向)
/last30days Listen Labs --hiring-signals
# ELI5 模式,同证据换普通话表达
说 "eli5 on",之后所有回复自动降解释门槛
5. 想把结果沉淀下来(可选):加 --store 就写进 SQLite。配合 scripts/watchlist.py 定时跑,配合 scripts/briefing.py 出周报。用来盯行业新闻、竞对动态、trip 前的目的地状态都合适。
阶段路线图(收藏用)
5 分钟:装 Skill,跑第一个免费主题(Reddit + HN + Polymarket + GitHub)。
1 小时:读一遍 ~/.config/last30days/.env,把 X 的 Cookie 或 XAI Key 挂上,YouTube yt-dlp 装好,ScrapeCreators 走 GitHub 一键授权。基本上所有主流社交平台都会点亮。
半天:拿三个自己关心的话题跑一遍,观察证据分布。比如"我关心的开源项目"、“我关心的领域领袖”、“我关心的一个宏观事件”。观察 v3 智能预研在这些话题上把哪些子来源判定为"该搜",这个判断能帮你反思自己平时的信息盲区。
长期:用 --store + watchlist.py + briefing.py 做个人情报流。参考 CONFIGURATION.md 里的 trend-monitoring 章节,可选加 Slack Webhook。
值得反过来警惕的几点
作为写代码的人,我不想把它吹成"AI 的终极调研工具"。几件需要自己判断的事:
- 它不能替你想问题。plan_query 再聪明,也只是根据你给的主题分解子问题。真正决定研究价值的是主题选得准不准。别指望"输入公司名字→输出董事会决议"。
- 来源不等于事实。Reddit 高赞可以是骂战胜利、可以是水军、可以是错误共识。管线保证的是"证据可追溯",不是"结论正确"。看简报的时候,遇到关键判断,还是要点回原始出处看一眼。
- Cookie 权限自查。它会读浏览器 Cookie,用于 X 登录态。开源代码本身可查,但你如果在共享机器上跑,注意别把整个 Chrome Cookie 库暴露给 Agent。macOS 用户可以用 Keychain 存 Key,减少落盘。
- v3 智能预研是一柄双刃剑。它有时候把主题解析得"太聪明",比如你想搜某个小众品牌,它可能推理成同名的知名品牌。搜错方向了,加
--no-entity-resolve或者显式提供 GitHub handle / subreddit。
适合谁 / 不适合谁
适合:
- 用 AI 做行业调研、竞品分析、人物研究、事件跟踪的人。
- 自己搭 Agent 工作流的开发者——它这套管线设计是可以抄的。
- 内容创作者做选题预研。
- Sales / BD 做客户前置研究。
不适合:
- 只想要一个"搜索框接 LLM"的场景。它比那个重。
- 想搜私有信息、内部资料。它只搜公开可访问的社交平台和网页。
- 不允许使用第三方 API 或浏览器 Cookie 的合规场景。
我抄进自己 Agent 的三个设计
写一整段总结不如列出具体可迁移的思路:
- available_sources + degrade 优雅降级:任何工具/Cookie/Key 不满足,把该来源标为不可用,管线继续跑。不要因为一个可选依赖挂掉整条链。
- weighted_rrf 跨源融合:不要按单一维度排序。把相关性、新鲜度、互动量、来源权重全部塞进 RRF,让"多源印证"的东西天然排前面。
- 每条结论必须能追回来源:
SourceItem结构强制携带原始链接和 handle。LLM 综合时被要求引用,看简报的人可以一键回溯。这是可信度的护栏,也是防止模型编造的最实用手段。
仓库:mvanhorn/last30days-skill · MIT · Python 3.12+
版本:v3.8.3(截至写稿)
主要作者:@mvanhorn;v3 引擎架构由 @j-sperling。
参考:
README.md— 项目定位、使用示例、支持的宿主AGENTS.md— 内部规则、CLI 门控、onboarding 契约CONFIGURATION.md— 全部环境变量、配置层优先级HERMES_SETUP.md— Hermes 用户的安装指南skills/last30days/scripts/lib/pipeline.py— v3 主管线skills/last30days/scripts/lib/planner.py— 主题→子问题的智能预研skills/last30days/scripts/lib/competitors.py—--competitors竞品自动化
以上内容基于源码、README、CHANGELOG、pyproject 元数据核对,未使用任何未验证的性能或效果宣称。