RedInk 源码拆解:把小红书图文生成做成一条可自部署流水线
如果你做过小红书图文,就知道最累的地方不是“写一句标题”,而是把一个想法拆成 6 到 12 页:封面怎么抓人,内容页怎么分层,每一页的字能不能放进图里,整组图片风格会不会跑偏,生成失败后怎么重来。
HisMax/RedInk 解决的正是这段流水线。它不是一个简单的图片生成壳子,而是把“小红书图文”拆成了几个明确步骤:先让文本模型生成大纲,再让用户编辑每页内容,随后调用图片模型批量生成封面和内容页,最后把历史记录和图片保留下来,方便重绘、下载和复用。
我看完 README、Dockerfile、前后端源码和配置模板后,最想强调一句:RedInk 的价值不在“AI 会不会画得更漂亮”,而在它把一个容易失控的内容生产过程做成了可配置、可回滚、可自部署的工具。
先看项目状态
几个可验证信息先放在前面:
- 仓库:
HisMax/RedInk - GitHub 描述:基于 Nano Banana Pro 的一站式小红书图文生成器,主打 “One Sentence, One Image”
- 主要语言:Python,后端是 Flask;前端是 Vue 3 + TypeScript + Vite + Pinia
- 本次 GitHub API 查询:约
5.3k+stars、1.0k+forks、16个 open issues - 最新浅克隆提交:
7413ddb fix: outline auto-save now works when recordId is missing (closes #47) - License 文件写的是
CC BY-NC-SA 4.0,并额外声明商业使用需要联系作者授权 - Docker 镜像:README 使用
histonemax/redink:latest
这几个点决定了它的适用边界:个人、学习、内部试验很合适;如果你要把它直接放进商业内容工厂,先处理授权问题。
它真正做了什么
普通图片生成工具回答的是:“给我一句提示词,我给你一张图。”
RedInk 更像在回答:“给我一个选题,我帮你拆成一组能发布的小红书图文,并且每页都能编辑、重绘和保存。”
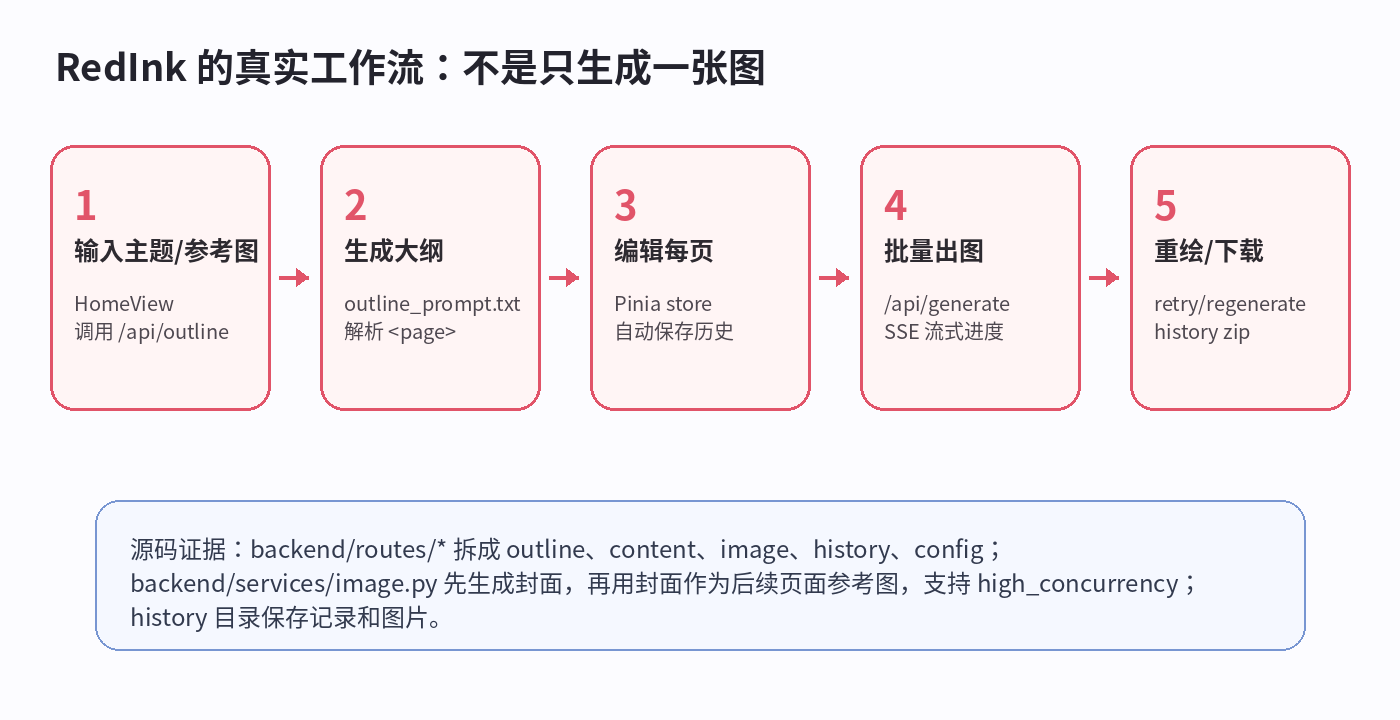
源码里的路径很清楚:
frontend/src/views/HomeView.vue收集主题和最多 5 张参考图,调用/api/outline。backend/routes/outline_routes.py解析表单或 JSON,交给backend/services/outline.py。backend/prompts/outline_prompt.txt要求模型用<page>分割页面,并标注[封面]、[内容]、[总结]。frontend/src/views/OutlineView.vue允许编辑、删除、插入、拖拽每一页,并自动保存。backend/services/image.py先生成封面图,再把封面作为后续页面的参考图,尽量保持整组风格一致。/api/generate通过 SSE 返回生成进度;失败的页面可以单独 retry 或 regenerate。backend/services/history.py把记录写入history/index.json和单条 JSON,图片也保存在history/<task_id>/下。
这就是它和“套个壳调用图片 API”的差别。RedInk 把“图文组”当成一个任务,而不是把每张图当成互不相关的请求。
源码里最值得借鉴的 4 个设计
1. 大纲先行,而不是直接出图
outline_prompt.txt 很强硬:第一页必须是封面;内容控制在 6 到 12 页;每页用 <page> 分割;每页开头必须标注类型。OutlineService._parse_outline() 再把模型返回解析成 pages 数组。
这个设计看似普通,其实很关键。因为小红书图文最容易翻车的地方是“每页各说各话”。先有页面级大纲,再出图,至少能让主题、页数和节奏先固定下来。
坏做法是:拿一个标题连发 9 次图片生成,让模型自己猜每页应该写什么。
好做法是:先把 9 页内容写清楚,再让图片模型只负责把每页变成视觉表达。
2. 封面作为风格锚点
在 backend/services/image.py 里,生成流程先处理封面页。成功后,它会读取封面图片并压缩到约 200KB,然后作为后续内容页的 reference_image。完整 prompt 里也写明:如果当前页面不是封面,要参考封面样式,保持配色、排版、字体和装饰元素一致。
这比单纯在 prompt 里写“风格统一”更可靠。模型至少看到了一个具体视觉锚点。
3. 配置分成文本模型和图片模型
RedInk 没有假设所有模型来自同一个供应商。配置模板明确分成两份:

text_providers.yaml:用于大纲、标题、文案、标签,支持openai_compatible和google_gemini。image_providers.yaml:用于图片生成,支持google_genai和image_api。
前端设置页会读写 /api/config,后端 config_routes.py 写入 YAML 时还会保留原有 API Key,并把返回给前端的 key 脱敏。这一点很实用:用户可以在 Web UI 里改模型、改 base_url、改 active_provider,而不用每次进服务器改文件。
4. 历史记录不是装饰功能
README 更新日志里提到 v1.4.1 修过“大纲生成后立即保存,编辑时自动保存”。这次浅克隆的最新提交也和 recordId 缺失时的大纲自动保存有关。
为什么这重要?因为图片生成是慢任务,而且可能因为限流失败。没有历史记录,用户刷新页面就丢;有历史记录,至少可以回到某个任务,查看大纲、重绘单张图、下载整组图片。
history_routes.py 里还提供了 /history/<record_id>/download,会把任务图片打成 zip。这是面向真实使用场景的细节。
5 分钟跑通:推荐先用 Docker
如果只是试用,不建议一上来本地装 Python、Node、pnpm、uv。README 推荐 Docker,一行就能启动:
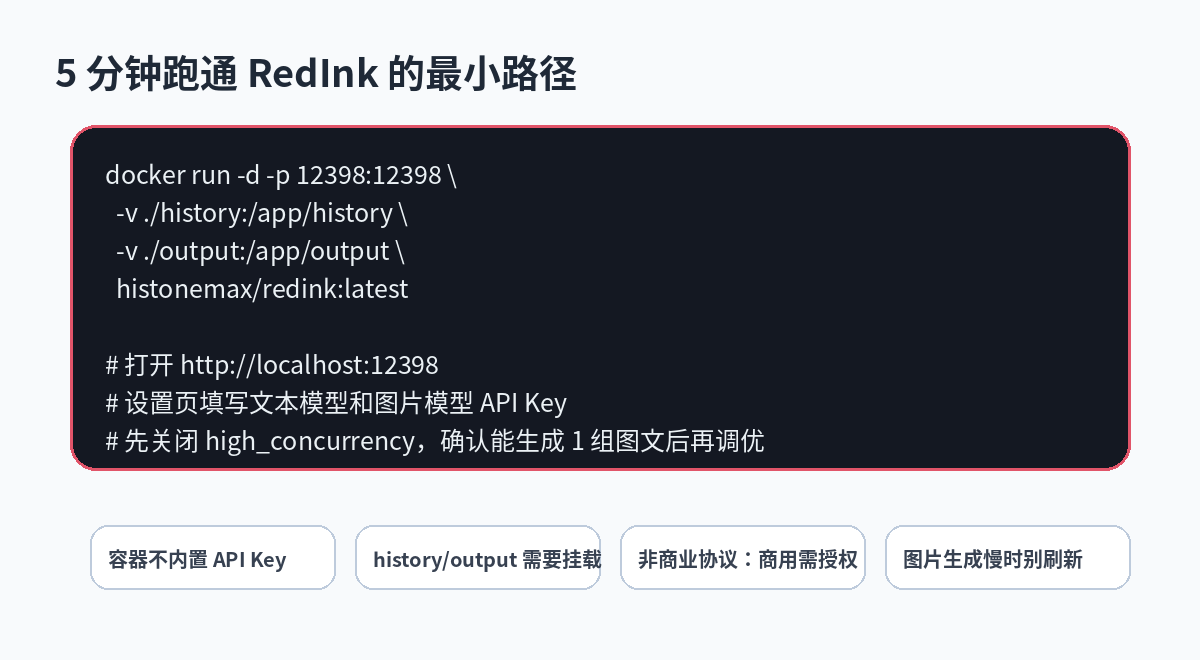
docker run -d -p 12398:12398 -v ./history:/app/history -v ./output:/app/output histonemax/redink:latest
然后打开:
http://localhost:12398
进入设置页,先配两类服务:
# text_providers.yaml 的思路
active_provider: openai
providers:
openai:
type: openai_compatible
api_key: sk-xxx
base_url: https://api.openai.com/v1
model: gpt-4o
# image_providers.yaml 的思路
active_provider: gemini
providers:
gemini:
type: google_genai
api_key: AIza...
model: gemini-3-pro-image-preview
high_concurrency: false
新手先别开高并发。README 明确提醒:GCP 300 美元试用账号不建议启用 high_concurrency,可能触发速率限制。等你确认单组图文能稳定生成,再考虑调并发。
本地开发怎么跑
如果你想改源码,可以走本地开发路径:
git clone https://github.com/HisMax/RedInk.git
cd RedInk
cp text_providers.yaml.example text_providers.yaml
cp image_providers.yaml.example image_providers.yaml
uv sync
cd frontend
pnpm install
手动启动:
# 后端,项目根目录
uv run python -m backend.app
# 默认 http://localhost:12398
# 前端,frontend 目录
pnpm dev
# 默认 http://localhost:5173
也可以直接运行项目提供的一键脚本:Linux/macOS 用 ./start.sh,Windows 用 start.bat。
一次完整使用建议
第一次使用,我建议不要从“大而全”的选题开始。用一个窄一点、可以判断好坏的题目,例如:
为一款 Java 后端学习路线生成 8 页小红书图文,风格简洁,少 emoji,重点突出学习顺序和避坑。
按这个顺序走:
- 输入主题,可选上传 1 到 3 张参考图。
- 先看大纲,不满意就改每页文字。尤其要检查封面标题是否过长。
- 点击生成前确认已经保存历史记录。
- 如果接口容易限流,先关闭高并发。
- 生成后先看封面,再看内容页是否风格统一。
- 只重绘失败或明显跑偏的页面,不要整组重来。
- 从历史记录下载 zip,保留原图。
小红书图文很吃文字可读性。模型生成的图如果文字太小、错字、漏字,再漂亮也不能直接发。RedInk 能把流程串起来,但最终审核还是要人来做。
适合谁,不适合谁
适合:
- 经常做小红书封面、知识卡片、课程图文的人。
- 想把“选题 → 大纲 → 成组图片 → 下载”做成固定流程的自媒体团队。
- 想研究 Flask + Vue + AI API 编排的开发者。
- 有多模型接口,希望自己控制配置和历史数据的人。
不适合:
- 只想偶尔生成一张海报的人,用通用生图工具更快。
- 对商用授权不敏感的人。这个项目的 License 不是宽松 MIT,而是 CC BY-NC-SA 4.0,商业使用要单独确认。
- 没有稳定图片模型额度的人。RedInk 的体验高度依赖图片生成接口质量和限流策略。
- 希望“完全自动发小红书”的人。RedInk 生成的是图文素材,不负责平台发布,也不替你做内容审核。
工程角度的几个坑
第一,Docker 部署一定要挂载 history 和 output。否则容器重建后,历史和产物很可能丢掉。
第二,配置文件不要提交到公开仓库。模板里虽然写了假 key,但真实 text_providers.yaml 和 image_providers.yaml 会保存 API Key。
第三,图片生成失败不一定是代码问题。401/403/404/429 在源码里都有明确报错分支,先看是不是 key、权限、模型名、base_url 或速率限制。
第四,高并发不是越高越好。ImageService 用 ThreadPoolExecutor 并发生成内容页,但供应商不支持时,只会把失败变多。
第五,生成图文之后还要人工校对。尤其是中文图片文字,错字和断句比普通文章更显眼。
我的判断
RedInk 最值得借鉴的不是“生成小红书图”这个表层卖点,而是它把一个内容生产动作拆成了稳定的工程流程:大纲是结构,封面是风格锚点,SSE 是进度反馈,历史记录是容错,配置页是模型抽象。
如果你只是想玩一下 AI 生图,它可能显得有点重;但如果你每周都要做成组图文,或者想给团队搭一个可控的素材生成台,RedInk 值得拉下来跑一遍。
别把它当魔法按钮。把它当一条流水线,效果会更接近真实生产。
参考
- GitHub 仓库:https://github.com/HisMax/RedInk
- 官方体验站:https://redink.top
- Docker 镜像:
histonemax/redink:latest - 关键源码:
backend/routes/*、backend/services/image.py、backend/prompts/*.txt、frontend/src/views/*、frontend/src/stores/generator.ts