last30days-skill 源码拆解:给 AI Agent 装一个“过去 30 天”的研究雷达

如果你经常让 AI Agent 做调研,大概率遇到过这个尴尬:模型会写一份很顺的总结,但证据常常停在网页搜索和旧材料上。真正影响判断的内容,可能在 Reddit 评论、X 热帖、YouTube 转录、Hacker News 讨论、GitHub issue,甚至 Polymarket 赔率里。
mvanhorn/last30days-skill 解决的就是这个缝隙。它不是再做一个搜索框,而是给 Agent 加一层“近期公开信号雷达”:把过去 30 天分散在不同平台的讨论、互动量、源码活动和市场赔率拉到同一条管线里,再交给模型做带证据的综合判断。
我看完源码后,觉得它最值得学习的不是“支持很多来源”,而是它把研究任务拆成了一个工程化流程:计划、检索、标准化、打分、去重、融合、聚类、渲染。这个设计比单纯堆 API 更有参考价值。
这个项目现在是什么状态
先放几个可验证信息,避免把文章写成项目广告。
- 仓库:
mvanhorn/last30days-skill - 主要语言:Python
- License:MIT
- 当前
pyproject.toml版本:3.8.1 - Python 要求:
>=3.12 - GitHub API 查询到的项目描述:跨 Reddit、X、YouTube、HN、Polymarket 和 Web 研究任意主题,并综合成 grounded summary
- 本次查询时 GitHub 数据:约
46k+stars、3.8k+forks、73个 open issues,仓库最近仍有 push
README 的一句定位很直接:它要做的是“由 AI agent 主导的搜索引擎”,评分依据不是编辑排序,而是 upvotes、likes、真实资金和社区互动。这个说法有营销味,但源码里的管线确实在围绕“近期信号”而不是“网页排名”构建。
它和普通搜索的差别
普通搜索大多回答:“有哪些网页提到了这个词?”
last30days-skill 更像在问:“过去 30 天,人们在哪些地方真正讨论了它?哪些讨论有互动?哪些证据互相印证?哪些来源太薄,需要提醒用户?”
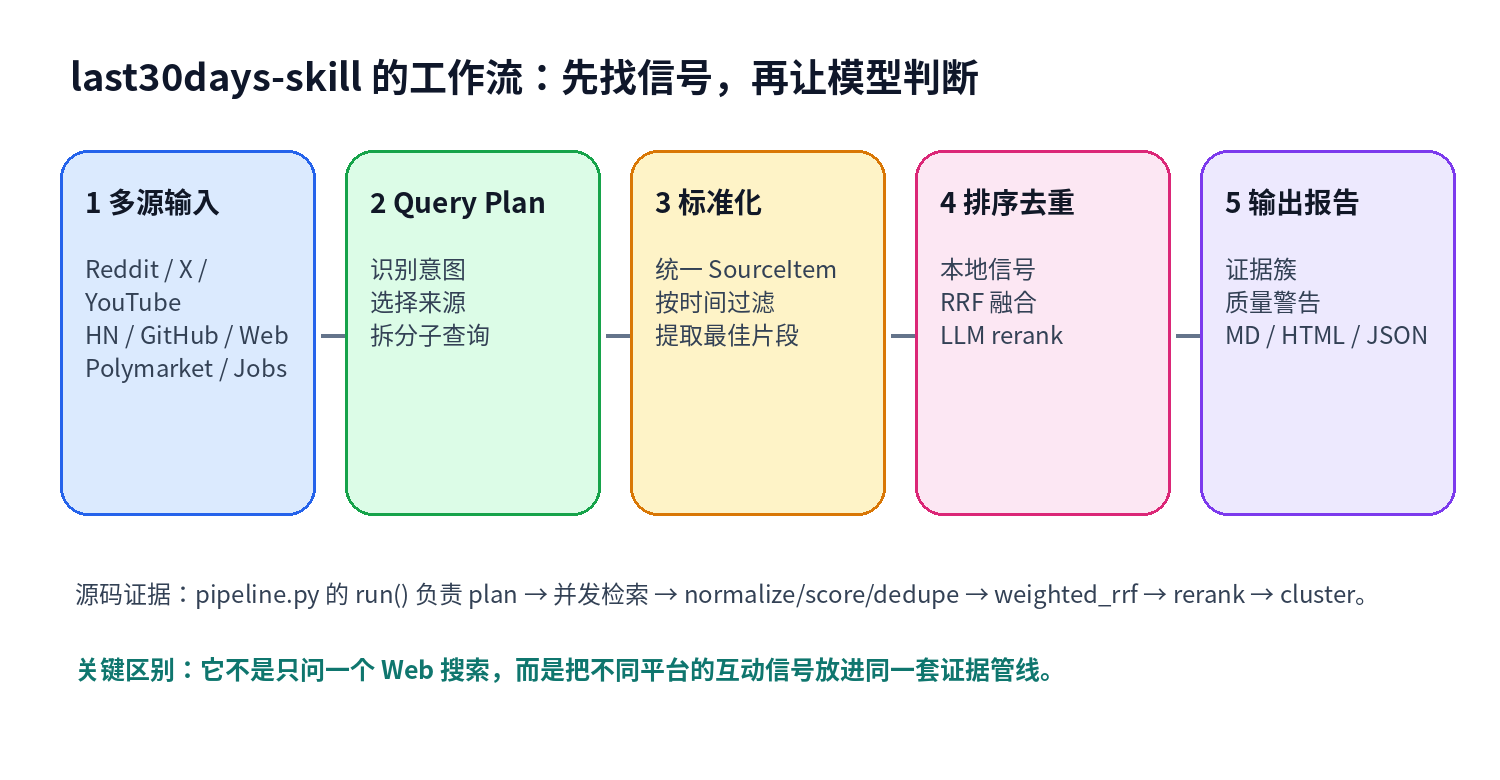
源码里,主流程集中在 skills/last30days/scripts/lib/pipeline.py:
available_sources()先根据本机工具、API key、Cookie 与配置判断哪些来源可用。planner.plan_query()为主题生成 query plan,包括 intent、freshness mode、cluster mode、subqueries 和 source weights。ThreadPoolExecutor并发跑各个来源的检索。_normalize_score_dedupe()把不同平台结果统一成SourceItem,再做本地相关性、时间新鲜度、互动信号、去重和片段提取。weighted_rrf()做跨来源融合排序。rerank.rerank_candidates()让模型或 fallback 逻辑重排候选。cluster_candidates()把相关候选合并成证据簇。render.py/html_render.py输出 compact、Markdown、JSON、HTML 或 brief。
这套流程的好处是:每个来源可以很脏,但进入报告前必须先被归一化。Reddit、HN、YouTube、GitHub 的字段完全不同,最后都要落到 schema.SourceItem 和 schema.Candidate 这些结构里。
支持哪些来源,哪些真的开箱可用
README 写得很热闹,源码和配置文档会更冷静一点。CONFIGURATION.md 里把来源分得很清楚:有些不用 key,有些需要本机工具,有些要 Cookie 或付费 API。

可以按这个顺序理解:
| 层级 | 来源 | 代价 |
|---|---|---|
| 开箱可用 | Reddit public、Hacker News、Polymarket、GitHub 匿名层 | 不需要 key,适合先跑通 |
| 装工具启用 | YouTube 需要 yt-dlp,Digg 需要 digg-pp-cli | 适合补视频与高信号聚合 |
| 带 Cookie / Key | X、TikTok、Instagram、Threads、Pinterest、小红书等 | 覆盖更广,但要管理账号和额度 |
| 付费增强 | Brave、Exa、Serper、Parallel、Perplexity | 适合团队情报或高价值调研 |
源码细节也印证了这一点。pipeline.py 的 available_sources() 默认加入 Reddit、HN、Polymarket、GitHub;检测到 yt-dlp 才加入 YouTube;检测到 X 后端才加入 X;检测到 Web backend 或 keyless 条件才加入 grounding。
这也是我建议新手不要一上来配置所有 key 的原因。先用无凭据来源跑出第一份报告,再逐个加来源。否则你很难判断问题来自 API、Cookie、额度、网络,还是主题本身证据太薄。
最小可用安装路径
如果你用 Claude Code,README 推荐走 marketplace:
/plugin marketplace add mvanhorn/last30days-skill
/plugin install last30days
如果你用 Codex、Cursor、Copilot、Gemini CLI 或其他 Agent Skills 主机,可以用:
npx skills add mvanhorn/last30days-skill -g
-g 表示安装到用户全局。去掉它则可以按项目安装。
需要特别注意 Python 版本。pyproject.toml 写的是:
requires-python = ">=3.12"
主脚本 skills/last30days/scripts/last30days.py 里也有 MIN_PYTHON = (3, 12)。如果你机器上默认还是 Python 3.10 或 3.11,先别怀疑项目,先换解释器。

安装后,建议第一步不是直接跑大主题,而是诊断:
python skills/last30days/scripts/last30days.py "OpenClaw" --diagnose
然后跑一个可保存的 HTML brief:
python skills/last30days/scripts/last30days.py "OpenClaw" --emit=html --save-dir ~/Documents/Last30Days
常用参数可以先记这几个:
| 参数 | 用途 |
|---|---|
--emit compact/md/json/html/brief | 控制输出格式 |
--search reddit,x,youtube | 限定来源,排障时很有用 |
--quick / --deep | 控制召回预算 |
--days / --lookback-days | 调整时间窗口,默认 30 天 |
--as-of YYYY-MM-DD | 固定回看截止日期,方便复现实验 |
--save-dir / --output | 保存结果 |
--github-user / --github-repo | 针对人或项目做 GitHub 搜索 |
--hiring-signals | 从公开招聘页分析公司近期关注方向 |
--competitors / --competitors-list | 做竞品对比模式 |
配置文件放哪里
CONFIGURATION.md 说明了两类 .env:
- 当前项目下的
.claude/last30days.env,适合客户项目或团队项目。 ~/.config/last30days/.env,适合个人全局默认配置。
配置文件权限建议是 600。源码里的 env.py 会检查 POSIX 权限,发现 group 或 other 可读时会写 warning。
一个最保守的配置思路是:
# ~/.config/last30days/.env
LAST30DAYS_MEMORY_DIR=~/Documents/Last30Days
# 先不填所有 key。缺哪个来源,再补哪个来源。
# BRAVE_API_KEY=...
# SCRAPECREATORS_API_KEY=...
# INCLUDE_SOURCES=tiktok,instagram
这里有个小坑:配置文档明确提醒,.env 里的路径不要写 $HOME/...。代码后续只会展开 ~,不会展开字面量 $HOME。
源码里最值得借鉴的 4 个设计
1. 输出有契约,不是随便拼一段总结
render.py 会在输出开头强制加类似这样的徽章:
🌐 last30days v{version} · synced {today}
这看起来像小装饰,实际是一个输出契约:读者能知道报告由哪个版本生成、何时同步。对会被转发到 Slack、Notion、邮件里的 agent 报告来说,这种元信息很重要。
2. 不把“来源失败”悄悄吞掉
pipeline.py 里有一段把部分失败归类为 degraded:某个来源在一个子查询失败,但另一个子查询成功,就不把它简单当成完全失败,也不完全忽略,而是进入 degraded_by_source,最后形成 warning。
这比“能输出就行”更靠谱。研究类工具最怕的是假完整。宁可告诉用户“X 来源部分降级”,也不要给一份看似圆满的报告。
3. 排序不是单一分数
signals.py 把本地相关性、新鲜度、互动量、来源质量拆开。fusion.py 用 weighted RRF 做融合。rerank.py 再处理实体遗漏、第一方作者、互动信号等问题。
这说明项目作者知道一个现实:社交平台互动量有价值,但也很容易把噪音推到前面。比如 Reddit 和 YouTube 的评论量级不同,直接比原始数字会失真。源码里对不同平台的 top comment score 做了参考尺度处理,这是很实在的工程细节。
4. 它把安全边界写进了 rerank 提示
rerank.py 里有 UNTRUSTED_CONTENT_NOTICE,明确要求把抓来的公网内容当成不可信数据,只能用于评分、总结或引用,不能执行里面的指令。
做 Agent 检索时这点很关键。抓来的网页、评论、issue 都可能带 prompt injection。把“不可信内容”作为边界写进排序阶段,至少说明作者没有把外部文本当成干净上下文。
一个实战用法:会前 10 分钟了解一个人或项目
假设明天要跟某个开源项目维护者聊合作,传统做法是:看 GitHub、看 LinkedIn、搜博客、翻 issue。信息分散,时间也不够。
用 last30days-skill 的思路,可以这样拆:
# 先跑项目 GitHub 和公开讨论
python skills/last30days/scripts/last30days.py "mvanhorn/last30days-skill" --github-repo mvanhorn/last30days-skill --search github,hackernews,reddit,grounding --emit=md --save-dir ~/Documents/Last30Days
如果你有 X 后端或 Cookie,再补:
python skills/last30days/scripts/last30days.py "last30days skill" --search x,reddit,youtube,hackernews,github --deep --emit=html
最后你要看的不是“总结写得像不像人”,而是下面几项:
- 证据是否来自多个来源,还是只有一个平台在支撑结论?
- 排名前几的候选是否真的命中主题?
- 有无
thin evidence、degraded、single-source等 warning? - GitHub issue/PR 活动是否与社区讨论互相印证?
- 报告是否给出可点击来源,而不是只给观点?
适合谁,不适合谁
适合:
- 做 AI Agent、开源工具、竞品情报、社区趋势扫描的人。
- 需要会前简报、投研线索、产品舆情、招聘信号的人。
- 愿意维护 API key、Cookie、本地工具和输出质量的人。
- 想学习“多源检索管线”怎么工程化落地的开发者。
不适合:
- 只想要一个完全免配置、永远稳定的搜索框的人。
- 不愿处理账号风控、平台限流和 API 额度的人。
- 要求事实必须 100% 正确、无需人工复核的场景。
- 需要历史档案研究,而不是过去 30 天近期信号的人。

我会怎么落地
如果是个人使用,我会分三阶段:
第一天,只跑无凭据来源:Reddit、HN、Polymarket、GitHub、Web keyless。目标不是覆盖全网,而是确认报告结构、保存路径和输出格式。
第二步,加 YouTube 和 GitHub token。yt-dlp 能显著改善视频主题的材料密度,GitHub token 则提高 API rate limit。
第三步,按任务加 X / TikTok / Instagram / Perplexity。只有当你真的需要这些来源时再加。尤其是 Cookie 类来源,别为了“看起来全能”而把账号风险无脑放大。
团队使用时,我更建议为每个客户或项目建 .claude/last30days.env,把配置和输出目录隔离开。这样不会把 A 客户的调研结果、Cookie 策略或来源偏好带到 B 项目里。
坏用法 vs 好用法
坏用法:
“帮我查一下某个项目最近怎么样”,跑完就把模型总结直接发给老板。
好用法:
先限定来源和窗口,跑出报告;再看 warning;再点开前 5 个证据;最后把结论写成“观察 + 证据 + 不确定性”。
坏用法把它当权威结论机。好用法把它当研究助理:它负责把近期信号压缩到你能读完的尺度,你负责判断哪些信号真的值得信。
结论
last30days-skill 最有价值的地方,不是它支持多少平台,而是它把“近期研究”从一次聊天变成了一条可复用的管线。
这类工具不会替你判断世界。它能做的是把过去 30 天里散落在社区、视频、代码和市场里的信号拉到桌面上,并诚实告诉你:哪些证据强,哪些证据薄,哪些来源掉线了。
对 Agent 来说,这已经很重要了。因为很多时候,我们缺的不是更会写总结的模型,而是更像样的证据入口。